 Image via 9to5Google / Google
Image via 9to5Google / Google Gemini 3.5 Flash Launches at Google I/O 2026: A Small Model That Outscores 3.1 Pro
Google launched Gemini 3.5 Flash today at I/O 2026. It posts 78% on SWE-Bench Verified, runs four times faster than other frontier models, and costs $0.50 input / $3 output per million tokens. Here's the launch in detail.
Google kicked off I/O 2026 in Mountain View this morning with the launch of Gemini 3.5 Flash, the company’s smallest current-generation model. The headline is a strange one: a Flash model that beats its own Pro sibling on most of the benchmarks Google chose to publish.
Tulsee Doshi, who runs product for the Gemini model team, framed it on stage as “the first in our next generation of models that combines frontier intelligence with lightning-fast action.” That phrasing matters. Google is not pitching this as a cheaper alternative to a flagship. It’s pitching the cheaper model as the flagship.
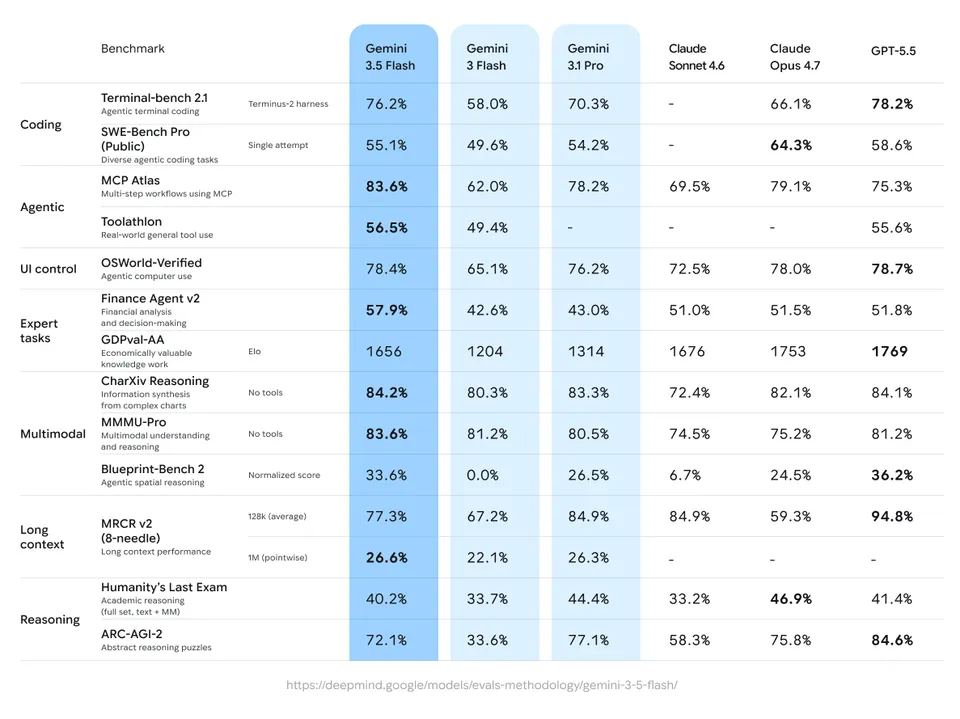
The Benchmark Story
Gemini 3.5 Flash posts numbers that, on paper, put it ahead of Gemini 3.1 Pro released in February:
- SWE-Bench Verified (agentic coding): 78%, up from Gemini 3.1 Pro’s 80.6% in the previous reporting and ahead of Gemini 3 Flash’s previous mark on the same test
- Terminal-Bench 2.1: 76.2%, a meaningful jump over the 68.5% Gemini 3.1 Pro posted on Terminal-Bench 2.0
- GDPval-AA: 1656 Elo, surpassing 3.1 Pro
- MCP Atlas: 83.6%, a new agent-tool benchmark Google introduced for this release
- CharXiv Reasoning (multimodal): 84.2%
According to Google’s own announcement, 3.5 Flash sits in the top-right quadrant of the Artificial Analysis Intelligence Index, balancing frontier-level intelligence with output speeds about four times faster than competing frontier models. A separately optimized version, Google says, runs 12 times faster at equivalent quality.
The benchmarks are not the whole story (they rarely are), but the relative position is. A Flash-tier model from one of the big labs is now matching or exceeding its own Pro tier from three months ago. That is the trend across every major AI provider in 2026, and it has direct consequences for how teams should think about model selection.
Pricing
Gemini 3.5 Flash is priced in line with the previous Flash generation:
| Standard rate | |
|---|---|
| Input | $0.50 / 1M tokens |
| Output | $3.00 / 1M tokens |
Context caching is on by default, giving up to 90% cost reductions on workloads with repeated token use beyond certain thresholds. The Batch API knocks another 50% off output costs for asynchronous jobs and ships with higher rate limits in exchange for the delay.
For comparison, Gemini 3.1 Pro is $2 input / $12 output (standard), four times more expensive on both sides of the meter for a model that 3.5 Flash now narrowly outperforms on coding and agentic benchmarks. Either Pro stops making sense for many use cases, or Google ships 3.5 Pro very soon. (Google confirmed the latter: 3.5 Pro is on the calendar for June 2026, positioned as an orchestrator while Flash runs sub-agent work underneath.)
Co-Developed With Antigravity
The detail buried in the Engadget coverage is the most interesting one for anyone building agent systems. According to TechCrunch’s report, 3.5 Flash was co-developed with Antigravity, Google’s agent-first coding platform. The model was trained, evaluated, and tuned on the same agent harness that Antigravity 2.0 (also launched today) now exposes to developers.
What this actually means: the gap between “running this model” and “running this model as an autonomous agent” has been collapsed inside Google’s training pipeline. The model is shaped by the same scaffolding that production agent systems use. Doshi’s claim during the keynote was that internal tests of Gemini 3.5 Flash, given long enough time horizons, “built an operating system from scratch” and managed independent coding pipelines and research projects without human intervention.
Take the marketing language with appropriate salt. The architectural choice underneath is real, and it shows in the Terminal-Bench and MCP Atlas numbers.
Availability
Gemini 3.5 Flash is rolling out today across every Google AI surface:
- Gemini app and AI Mode in Google Search as the default model, globally
- Gemini API through Google AI Studio
- Google Antigravity 2.0 (desktop app, CLI, and SDK)
- Android Studio via Gemini integration
- Vertex AI for enterprise
- Gemini Enterprise Agent Platform
Existing Gemini API users get the model with no action required. The model name in the API is gemini-3.5-flash. Code that previously routed to gemini-3-flash will continue to work; Google has not announced a deprecation date for the previous generation.
How This Changes Model Selection
A few situations where it’s worth re-evaluating:
You’re using Gemini 3.1 Pro for agentic coding. Test 3.5 Flash against your evals. If it holds, you cut model cost by roughly 75% and get higher rate limits. The places where Pro will still win are long-context reasoning workloads where Pro’s Deep Think integration matters, and certain GPQA-style scientific knowledge tasks where Pro still has the lead.
You’re using a different provider’s Flash-tier model for code. Gemini 3.5 Flash’s SWE-Bench Verified score now sits in striking distance of Claude Sonnet 4.6 and well ahead of GPT-5.3-Mini for agentic coding tasks specifically. The price point ($0.50/$3) makes it the cheapest model with that level of agent performance.
You’re building anything that runs as a long-horizon agent. The Antigravity co-development is the relevant detail. Whatever production system Google built internally to test these long-horizon claims is the same harness now exposed through Antigravity SDK and Managed Agents. If you want to run multi-hour autonomous tasks, this stack is now Google’s recommended path.
You’re cost-sensitive and don’t need frontier reasoning. Flash-tier models from the major labs have crossed the line where they handle 80% of production workloads. Gemini 3.5 Flash is the strongest example of this in May 2026. For chat backends, summarization, classification, and routine code assistance, the math has shifted toward the cheaper tier.
The Bigger Picture
The interesting thing about a Flash model outperforming a three-month-old Pro is that it tells you the rate at which “frontier” capability is being squeezed into smaller, cheaper inference. The Pareto frontier moved meaningfully today.
Whether that lasts depends on what Anthropic and OpenAI ship in the next eight weeks. Both companies are due for cycle releases, and both have historically responded fast to Google announcements. But for today, Google has the most cost-effective frontier-class model on the market, and they shipped it on the same morning they re-launched their agent platform around it. That is not a coincidence.
For developers, the practical move is the same as ever: run it against your actual workloads before believing the chart. Benchmarks set expectations. Your evals tell the truth.
Sources:
- Google Blog: Gemini 3.5 announcement
- Google Blog: Build with Gemini 3 Flash
- TechCrunch: With Gemini 3.5 Flash, Google bets its next AI wave on agents
- Engadget: Google says Gemini 3.5 Flash rivals large flagship models
- Android Authority: Gemini 3.5 Flash is here
- 9to5Google: Google I/O 2026 news roundup
- Gemini Developer API pricing