 Cursor
Cursor Cursor's Composer 2.5 Matches Opus 4.7 on Benchmarks at One-Tenth the Cost
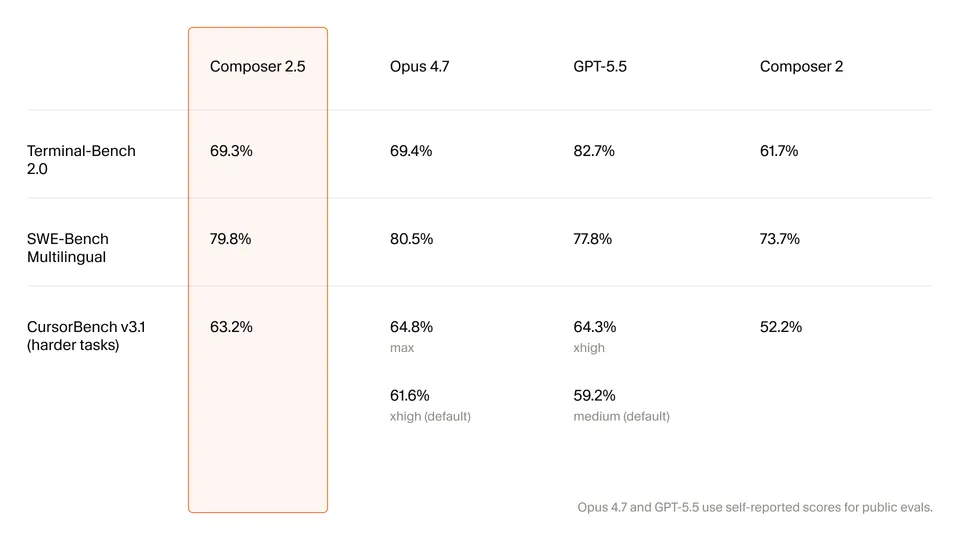
Cursor released Composer 2.5 on May 18, built on Moonshot's Kimi K2.5 checkpoint with 85% of compute spent on Cursor's own post-training pipeline. It scores 63.2% on CursorBench v3.1, edging out both Opus 4.7 and GPT-5.5 at a fraction of the inference cost.
Cursor released Composer 2.5 on May 18, and the headline number is $0.50 per million input tokens. For context, Claude Opus 4.7 and GPT-5.5 both run at $15 per million input — roughly 30 times more expensive. The model is live in Cursor now.
The benchmark story is the interesting part. Composer 2.5 scores 63.2% on CursorBench v3.1, Cursor’s internal agentic coding evaluation. Opus 4.7 at its default “xhigh” effort level scores 61.6%. GPT-5.5 at medium effort scores 59.2%. Whether those numbers hold in real-world use is always a question, but the direction is clear enough: Cursor has trained a model that trades cost for performance in a way that narrows the gap significantly.
What’s under the hood
Composer 2.5 starts from Moonshot AI’s Kimi K2.5 open-source checkpoint. Cursor then spent 85% of the total compute budget on their own post-training pipeline — reinforcement learning, continued pretraining, and a new technique they call targeted textual feedback.
The targeted feedback method addresses a known limitation in RL training for coding tasks: when a model runs a 50-step trajectory and fails, the failure signal is noisy about which specific steps caused the problem. Cursor’s approach inserts localized hints at the exact points in the trajectory where the model diverged from useful behavior, then distills that feedback back into the weights. The idea is to make credit assignment more precise rather than propagating a diffuse reward signal across every decision.
Training data also scaled up: 25 times more synthetic tasks than Composer 2, including an approach called feature deletion where a model is asked to reimplement code it can no longer see, verified by tests rather than by reference to the original.
On SWE-Bench Multilingual, Composer 2.5 scores 79.8%. The technical details include Sharded Muon and Dual Mesh HSDP optimization techniques, which Cursor says achieved a 0.2-second optimizer step time on the trillion-parameter model.
Pricing tiers
There are two pricing options. The standard tier runs $0.50 per million input tokens and $2.50 per million output tokens. A fast variant with the same intelligence runs $3.00 input and $15.00 output — the same output cost as the Opus/GPT-5.5 tier but still cheaper on input.
Cursor is offering double usage for the first week as a promotional launch offer.
What comes next
Cursor mentioned a collaboration with SpaceX AI on training a significantly larger model using 10 times more total compute. No timeline given.
The Kimi K2.5 base is notable because it’s open-source. Cursor’s bet is that the proprietary value is in the post-training, not the foundation model — and that by starting from a strong open checkpoint and running a purpose-built RL pipeline on top, they can close the performance gap to frontier closed models at a fraction of the serving cost. Composer 2.5 is the first public demonstration of whether that bet pays off.
Source: Cursor Composer 2.5 blog post, changelog